In the middle of May, during Radical Speed Month at Automattic, the first nightly deployment of WooCommerce shipped to production at WooCommerce.com (WCCOM for short, to keep it distinct from the WooCommerce plugin). I’d be lying if I said it wasn’t a bit scary. And sure enough, within hours, we caught a real performance regression that we reported upstream before it reached any public release.
Why did we even do it? To catch potential regressions in WooCommerce as early as possible, so WooCommerce itself is more stable.
WCCOM is itself a production WooCommerce store: it sells extensions, processes payments, and has real traffic (~1.4M visitors every month). Every weekday, a pipeline pulls the latest nightly build, deploys it to a staging environment, runs tests, and produces a ready-to-merge pull request.
The idea is inspired by how WordPress.org runs on WordPress trunk. You run code early, are sometimes affected by a bug or two, but can recover from it quickly, patch upstream, and ensure that when the proper release goes out, it’s more stable for everyone.
What we actually built
Here’s what the pipeline looks like:
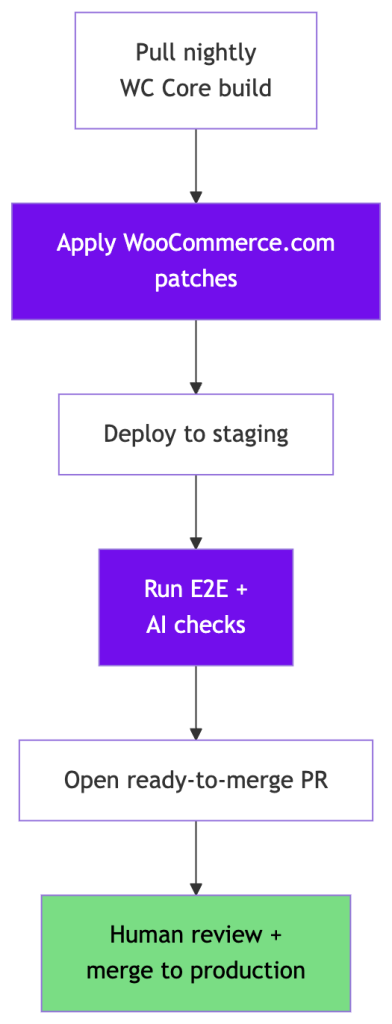
AI handles the purple steps, but a human still owns the merge (more on that later): someone reads the generated output and decides if we ship it to WCCOM or not.
Most of this is the usual infrastructure: cron and CI and deploy gates. The interesting part is three jobs that are automated now:
- Patch replay – We run a slightly patched WC Core on WCCOM (the patches are small fixes we’re sending back upstream to Core or Action Scheduler, carried here only until they land in a release), and those patches have to be reapplied on top of a new core. An LLM reads our patch manifest, decides per patch whether each one is still needed, already upstreamed, or needs adjusting, and commits the result.
- AI review of the Core diff – A large core diff was never going to get a real human review from our side, so an LLM does a focused pass on the integration points where Core meets our code and posts a verdict on whether the PR is safe to merge or not.
- Exploratory testing on staging – After each upgrade deploys, an agent walks the key flows and files what it finds as PR comments. It’s an additional pass that’s supposed to supplement our regular E2E tests.
What we caught in the first two weeks
Week 1. The very first run flagged a broken integration test, traced to a specific upstream change. Upstream had already pushed a revert by the time I looked, but on a daily cadence we’d have caught it sooner.
Week 2. This was the more interesting one. A few hours after the upgrade shipped, I was in Grafana and saw slow queries on order metadata climbing right around deploy time. After digging into it more, I found the cause was an upstream PR that dropped the composite (meta_key, meta_value) index on wp_wc_orders_meta and replaced it with a single-column one. Reasonable change on its own and for WooCommerce Core itself, as no queries originating from WC Core needed the index. But it didn’t account for queries made by extensions. On our store, several extensions ran queries that relied on the composite version, and on production they blew up, mostly from WooPayments and Subscriptions, with subscription renewal lookups averaging ~34s and scanning ~2.5M rows each.
I reapplied a composite index on our site the same day to mitigate it and reported it upstream with the slow-query data. A better-performing index has since been shipped in WC 10.8 (we tested its shape on WCCOM). We caught it before it could reach a public release, which was the whole point of updating WooCommerce on WCCOM every day.
What was AI actually useful for
Just to be clear, the AI gates didn’t catch the slow-query regression. The diff review and the exploratory agent both passed the upgrade, and I only caught the slowdown afterwards in Grafana.
Where AI actually did help was taking over three jobs that used to be expensive enough that we only ran them at release cadence:
- AI review of Core diffs. We weren’t doing this at all, because the diffs were too big to read by hand when we were doing WooCommerce updates on regular release cadence.
- Exploratory testing on staging. We did it manually around releases, and it cost us time.
- Patch replay. We did it carefully, and it was a chore I was happy to hand off.
With AI doing this work, our small team can update WooCommerce on WCCOM continuously, instead of doing it only when the full release is ready.
AI also helped us a lot with test coverage. Claude ran Playwright MCP against a dev site (no production data on it) and iterated on integration and E2E tests, saving us hours of work.
Where AI is far from perfect, for now
AI-owned parts of the pipeline are useful but not perfect. Two that still need work:
- The AI reviewer’s first verdicts were useless. Too generic, missing the real risks. We rewrote the prompt to focus mostly on the integration points with our code, and I’m sure we’ll iterate on it a few more times.
- The exploratory agent is promising but still in an early phase. It files findings as PR comments, but the flows it covers still need tuning as we learn what shows up on upgrade diffs.
What this means for you
If you build on top of WooCommerce: WCCOM running on the nightly build of WooCommerce makes WooCommerce more stable (but remember that even WCCOM does not use every WooCommerce feature, so some flows are not tested on WCCOM at all).
If you contribute to WooCommerce Core: Your code hits a production site (WooCommerce.com!) within a day of merging to trunk. If something breaks our integration or slows down WCCOM, you’ll hear about it within hours or days, not after the full release.
And finally, what’s next
Next, I want to focus on more automation and fewer manual steps. It’s early in the process, and every deployment to production requires some amount of post-deployment monitoring. Adding missing telemetry as a core part of the upgrade (slow-query anomaly detection, error-rate comparisons, latency percentiles), and automatically notifying the right people when something breaks, will take the manual monitoring out of the loop and free up our time for more interesting activities.
Co-reviewed and frequently paired with Cem Ünalan. Thanks to the rest of the WooCommerce.com engineering team for support along the way.
Leave a Reply